
関連記事プラグイン「WordPress Related Posts」のメリット・デメリット
関連記事の表示はサイトの回遊率を上げるのに非常に有効な手段です。
WordPressでは関連記事を取得する機能はないため、プラグインを利用したり自分で実装する必要があります。
試しに「wordpress 関連記事 プラグイン」で調べてみるとそれらしい記事はたくさんヒットします。
上位サイトを覗いてみたところ多くのサイトで「WordPress Related Posts」を紹介していました。
有効インストール数は100000以上でとても人気のプラグインのようです。
プラグインを開発している身としては、どうしてそんなに人気があるのか気になります。
実際にダウンロードして色々と調べてみました。
紹介されている内容として多くあったのは「デザインが複数」や「設定が簡単」などでした。
さっそくプラグインを有効化して確認してみます。
するとまだ何も設定していないにもかかわらず記事の最後に関連記事が表示されるようになりました。
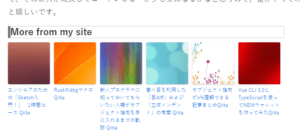
あとは関連記事のタイトルが変えられればとりあえずは問題なさそうです。
プラグインの設定画面を確認してみます。
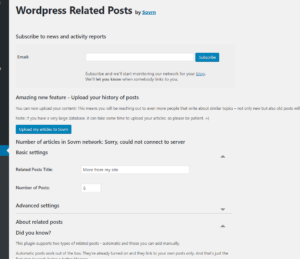
日本語化されていませんがこの時点で設定の数はたったの2つしかなく、さきほど変えたいと思ったタイトルの変更箇所がすぐにわかります。
さらに「Advanced settings」を開くと細かい設定が出てきます。
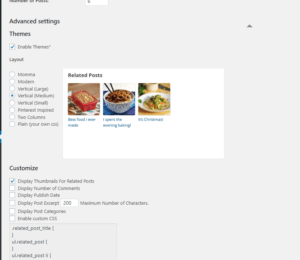
評判通り色々なデザインがあらかじめ用意されているようです。
選択肢をホバーすればどのようになるのかがすぐわかるので、いちいち保存して確認しに行く必要がありません。
タイトルを変更してデザインも好きなものを選んで保存すれば求めていたことが実現されることでしょう。
普通にブログを書いている人からすればきっとそう思うでしょう。
簡単に かつ 十分にきれいな関連記事が表示さえされれば、普通の利用者はこのプラグインが裏でどのような動作をしているかは気にならないものです。
では実際にこのプラグインが裏で行っている処理を見ていきましょう。
有効化と同時にこのプラグインは以下の情報をMixpanelというサービスに送信します。
Mixpanelというサービスはアクセス解析などに使用されるものです。
あなたがこのプラグインを有効化したという情報はサーバの情報とともに収集されています。
こういった情報が送信されることを事前に理解していましたか?
一応プラグインページに利用規約のリンクがありますがリンク切れです。
プライバシーポリシーとして載っているほうのリンクは見ることができます。
こちらには一応IPを含むブラウザや端末を識別するための個人情報を集めることやそれをサードパーティに提供すること、利用状況を監視することが書いてあります。
しかしブラウザや端末を識別するための個人情報に関する記述はありましたが、サーバの情報を収集する記述は見つかりません。
結局サーバの情報などをサードパーティに提供することは知らされていません。
さらに利用規約がリンク切れであるため、このプライバシーポリシーまで確認する人はほとんどいないのではないでしょうか
もっと言えばIPアドレスなどはハッシュ化すると書いてあるのにハッシュ化せずに使用しているのも問題です。
「WordPress Related Posts」の設定画面にアクセスすると、一日に一回サーバの情報と紐づいた情報が送られます。
利用規約の通り、あなたがこのプラグインを使用しているということは監視されています。
想像通りだと思いますが、この時も無効化したという情報を送信してくれます。
あなたがこのプラグインを使わなくなったということが、あなたのサーバの情報とともに送られます。
「WordPress Related Posts」の設定画面を開くたびに「Zemanta」というサービスと連携するために
というAPIにアクセスします。
少し古い記事を見てみたところ、かつては携帯端末とPCとでクリック率等を表示するために使用していたサービスのようで、有効化するときにサービス利用規約的なのに同意するといった文言があったようです。
前述のように今は稼働していないようです。
tf-idfのようなもので算出しているようです。
tf-idfは関連記事を求めるのによく使われる手法なので、アプローチとしては正しいです。
ただ日本語記事の場合はこのプラグインの処理では意味のあるものにはなっていません。
tfとは単語の出現頻度、すなわち記事の中にある単語がどのくらい含まれているかの割合です。
このプラグインではtfは「タグ」と「カテゴリ」と「タイトルと本文から抽出した単語」をそれぞれ重みづけしたもので導出しています。
重みはタグは10倍、カテゴリーは5倍、単語は2倍になっています。
ただし「タイトルと本文から抽出した単語」は以下のような処理で抽出されています。
いろいろ処理をしていますが日本語に関しては全く考慮されていません。
実際にQiitaで見つけた適当な記事で抽出された単語をvar_dumpしてみた結果です。
HTMLのタグや数字が多く含まれています。
これらからどれだけ記事が似ているか判断できるでしょうか?
idfとは逆文書頻度、すなわち全ての記事でどのくらいその単語が使用されているかの割合の逆数です(単語のレア度)。
先ほどの処理内容の3.2に相当します。
あなたが投稿した記事からではなく、このプラグインの提供している辞書から判定しています。
この辞書はもちろん英語にしか対応していないため日本語ではほとんど意味はありません。
タイトルや本文からは意味のない評価値しか得られないため、結局のところ「タグ」と「カテゴリ」のみで判定されているようなものです。
それであれば先に挙げたような無駄な処理は不要で、同じタグやカテゴリを持つ記事をランダムでとってきてもさほど違いはないと思います。
このプラグインのメリットは無意味な処理で機械的に算出された関連記事よりも、記事画面から手動で好きな記事を関連記事として簡単に登録できる点にあると思います。
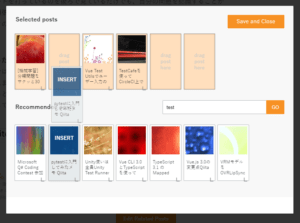
この機能は操作感もよく直観的で、非常に素晴らしいものです。
WordPressの関連記事を検索してきたときに上位に出てくるサイトでよく称賛されているプラグインだとしても、裏ではいろいろな情報を勝手に取得している場合があります。
本来は個人を特定できないCookieでさえプロファイルで特定可能だとか色々言われて個人情報保護が謳われている今日において、同意を得ていない情報を第三者に送信するのは問題ないのでしょうか。
デザインの重要性や導入・設定の容易さは見習うべきところがあり、今後のプラグイン開発に生かしていきたいです。
WordPressでは関連記事を取得する機能はないため、プラグインを利用したり自分で実装する必要があります。
試しに「wordpress 関連記事 プラグイン」で調べてみるとそれらしい記事はたくさんヒットします。
上位サイトを覗いてみたところ多くのサイトで「WordPress Related Posts」を紹介していました。
有効インストール数は100000以上でとても人気のプラグインのようです。
プラグインを開発している身としては、どうしてそんなに人気があるのか気になります。
実際にダウンロードして色々と調べてみました。
WordPress Related Posts の特徴
紹介されている内容として多くあったのは「デザインが複数」や「設定が簡単」などでした。
さっそくプラグインを有効化して確認してみます。
するとまだ何も設定していないにもかかわらず記事の最後に関連記事が表示されるようになりました。

あとは関連記事のタイトルが変えられればとりあえずは問題なさそうです。
プラグインの設定画面を確認してみます。
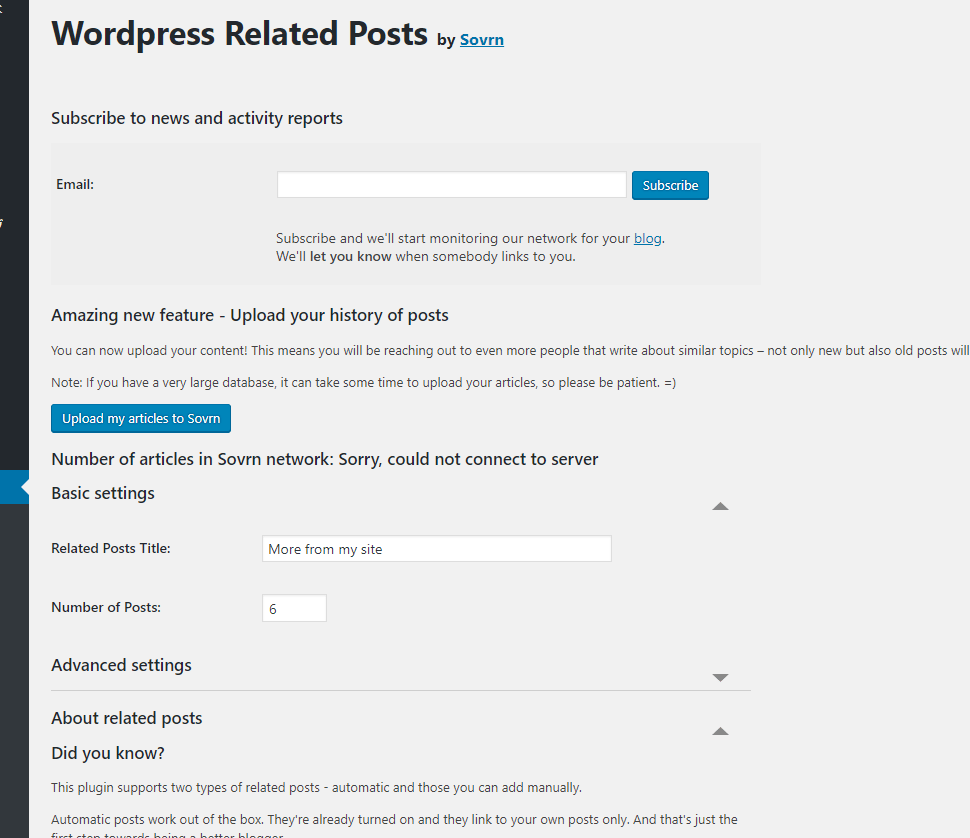
日本語化されていませんがこの時点で設定の数はたったの2つしかなく、さきほど変えたいと思ったタイトルの変更箇所がすぐにわかります。
さらに「Advanced settings」を開くと細かい設定が出てきます。

評判通り色々なデザインがあらかじめ用意されているようです。
選択肢をホバーすればどのようになるのかがすぐわかるので、いちいち保存して確認しに行く必要がありません。
タイトルを変更してデザインも好きなものを選んで保存すれば求めていたことが実現されることでしょう。
非常に有用なプラグイン
普通にブログを書いている人からすればきっとそう思うでしょう。
簡単に かつ 十分にきれいな関連記事が表示さえされれば、普通の利用者はこのプラグインが裏でどのような動作をしているかは気にならないものです。
では実際にこのプラグインが裏で行っている処理を見ていきましょう。
プラグインを有効化したとき
有効化と同時にこのプラグインは以下の情報をMixpanelというサービスに送信します。
- サイトのホスト名
- サーバーのIP
- サーバーのPHPのバージョン
- このプラグインを有効化したという情報
- 操作した時間
Mixpanelというサービスはアクセス解析などに使用されるものです。
あなたがこのプラグインを有効化したという情報はサーバの情報とともに収集されています。
こういった情報が送信されることを事前に理解していましたか?
一応プラグインページに利用規約のリンクがありますがリンク切れです。
プライバシーポリシーとして載っているほうのリンクは見ることができます。
こちらには一応IPを含むブラウザや端末を識別するための個人情報を集めることやそれをサードパーティに提供すること、利用状況を監視することが書いてあります。
しかしブラウザや端末を識別するための個人情報に関する記述はありましたが、サーバの情報を収集する記述は見つかりません。
結局サーバの情報などをサードパーティに提供することは知らされていません。
さらに利用規約がリンク切れであるため、このプライバシーポリシーまで確認する人はほとんどいないのではないでしょうか
もっと言えばIPアドレスなどはハッシュ化すると書いてあるのにハッシュ化せずに使用しているのも問題です。
設定画面に毎日アクセスしてみる
「WordPress Related Posts」の設定画面にアクセスすると、一日に一回サーバの情報と紐づいた情報が送られます。
利用規約の通り、あなたがこのプラグインを使用しているということは監視されています。
無効化時
想像通りだと思いますが、この時も無効化したという情報を送信してくれます。
あなたがこのプラグインを使わなくなったということが、あなたのサーバの情報とともに送られます。
設定画面にアクセス時
「WordPress Related Posts」の設定画面を開くたびに「Zemanta」というサービスと連携するために
http://api-ea.sovrn.com/services/rest/0.0/
というAPIにアクセスします。
少し古い記事を見てみたところ、かつては携帯端末とPCとでクリック率等を表示するために使用していたサービスのようで、有効化するときにサービス利用規約的なのに同意するといった文言があったようです。
前述のように今は稼働していないようです。
どのような判断で関連記事を決めているか
tf-idfのようなもので算出しているようです。
tf-idfは関連記事を求めるのによく使われる手法なので、アプローチとしては正しいです。
ただ日本語記事の場合はこのプラグインの処理では意味のあるものにはなっていません。
tfの算出
tfとは単語の出現頻度、すなわち記事の中にある単語がどのくらい含まれているかの割合です。
このプラグインではtfは「タグ」と「カテゴリ」と「タイトルと本文から抽出した単語」をそれぞれ重みづけしたもので導出しています。
重みはタグは10倍、カテゴリーは5倍、単語は2倍になっています。
ただし「タイトルと本文から抽出した単語」は以下のような処理で抽出されています。
- 「タイトルを空白で分割した集合」と「本文を空白で分割した集合」を合わせて先頭から200件取得(⇒英語の文章であれば単語の集合になるが日本語では…)
- それぞれの単語に対して、
- 小文字に変換
- 英単語に使われるような文字(アルファベットや数字)以外を削除(もはや日本語は含まれない)
- 英単語の正規化
- 使用頻度を集計
- それぞれの集計された単語に対して
- 辞書登録された単語かどうか判定(lib/unigrams.csv)
- 「辞書登録された恐らく様々な文章から集計した単語の使用頻度の逆数(idfに相当)と思われる値」と「記事内での疑似的な使用回数をルート2した値」を掛けた値を評価値として保存(tf-idfとは違うが似たような値)
- 評価値の高い順に並び替えて先頭の15個の単語を「タイトルと本文から抽出した単語」として使用
いろいろ処理をしていますが日本語に関しては全く考慮されていません。
実際にQiitaで見つけた適当な記事で抽出された単語をvar_dumpしてみた結果です。
array (size=6)
'idc' => float 0.038011695906433
'ls' => float 0.025296442687747
'div' => float 0.020052770448549
10 => float 0.013195470211718
'a' => float 0.009815123425433
'id' => float 0.0072491278699008
array (size=22)
'wip' => float 0.10532994923858
'app' => float 0.10421374296051
'lili' => float 0.093619341937829
'lia' => float 0.069284064665127
'ul' => float 0.050354609929078
'api' => float 0.045795543612138
'code' => float 0.04433888441912
'rust' => float 0.043381535038932
'div' => float 0.040105540897098
'hook' => float 0.034950692551906
'github' => float 0.032662192393736
'cargo' => float 0.028380423814329
'li' => float 0.023232382997962
'ol' => float 0.020092041755528
'releas' => float 0.018155341509202
'ci' => float 0.017123287671233
'a' => float 0.017000292455409
'url' => float 0.0097022044566265
'span' => float 0.0071037315987675
'warn' => float 0.0069141235740344
'merg' => float 0.0046314780803322
'id' => float 0.0041852859270773
array (size=4)
'aa' => float 0.042318634423898
'div' => float 0.028358899931492
'span' => float 0.016659727322207
'id' => float 0.0059188881204819
array (size=19)
'app' => float 0.18050349765452
'googl' => float 0.095306368156461
'alt' => float 0.081311562818174
'h2' => float 0.073587385019711
'gt' => float 0.055269922879177
'ga' => float 0.054751778921616
'aa' => float 0.042318634423898
'a' => float 0.040468790611534
8 => float 0.040403893255304
'script' => float 0.030460274827131
42 => float 0.022950819672131
1 => float 0.022224657133987
'div' => float 0.020052770448549
5 => float 0.019731872160836
58 => float 0.012737501326823
45 => float 0.0076729776908174
23 => float 0.0070726915520629
'id' => float 0.0059188881204819
56 => float 0.0051706308169597
HTMLのタグや数字が多く含まれています。
これらからどれだけ記事が似ているか判断できるでしょうか?
idfの算出
idfとは逆文書頻度、すなわち全ての記事でどのくらいその単語が使用されているかの割合の逆数です(単語のレア度)。
先ほどの処理内容の3.2に相当します。
あなたが投稿した記事からではなく、このプラグインの提供している辞書から判定しています。
この辞書はもちろん英語にしか対応していないため日本語ではほとんど意味はありません。
評価値の算出
タイトルや本文からは意味のない評価値しか得られないため、結局のところ「タグ」と「カテゴリ」のみで判定されているようなものです。
それであれば先に挙げたような無駄な処理は不要で、同じタグやカテゴリを持つ記事をランダムでとってきてもさほど違いはないと思います。
このプラグインのメリット
このプラグインのメリットは無意味な処理で機械的に算出された関連記事よりも、記事画面から手動で好きな記事を関連記事として簡単に登録できる点にあると思います。
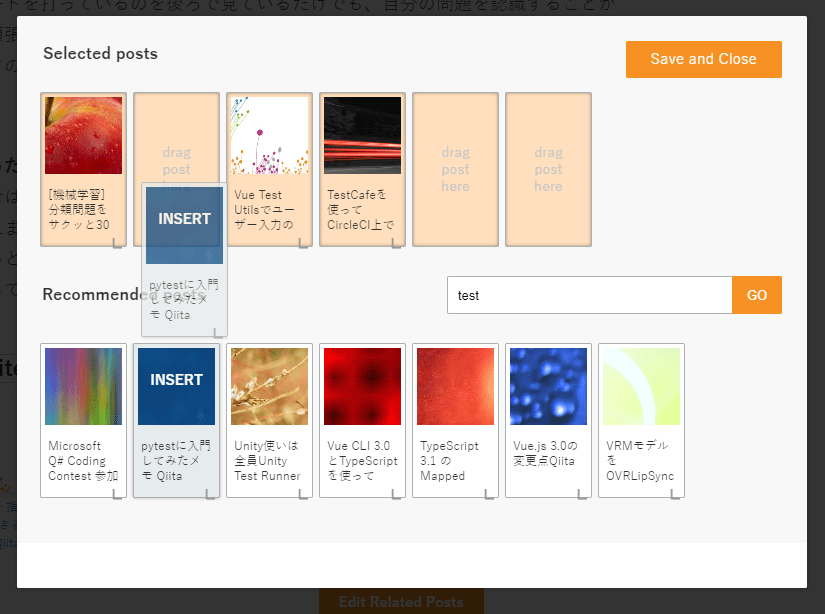
この機能は操作感もよく直観的で、非常に素晴らしいものです。
まとめ
WordPressの関連記事を検索してきたときに上位に出てくるサイトでよく称賛されているプラグインだとしても、裏ではいろいろな情報を勝手に取得している場合があります。
本来は個人を特定できないCookieでさえプロファイルで特定可能だとか色々言われて個人情報保護が謳われている今日において、同意を得ていない情報を第三者に送信するのは問題ないのでしょうか。
デザインの重要性や導入・設定の容易さは見習うべきところがあり、今後のプラグイン開発に生かしていきたいです。
Makefile で 動的にコマンドを変える方法
